Update, February 3rd 2025: It's been a couple of years, and by now, this article is extremely outdated. In fact, it was rendered obsolete roughly two weeks after its publication, when Stable Diffusion was released to the public. The technical bits aren't that interesting anymore, but I think the legal and ethics parts, such as they are, have held up.
I recently got access to OpenAI's DALL-E 2 instance. It's a lot of fun, but beyond its obvious application as a cornucopia of funny cat avatars, I think it's now fit to use in certain kinds of creative work.
There are already plenty of good articles out there on the model's strengths and weaknesses, so I won't go over that here other than to note that it's not a threat to high-end art. It's got an idea of what things look like and how they can visually fit together, but it's very vague on how they work (e.g. anatomy, architecture, the finer points of Victorian-era dinner etiquette, art critics), and object inpainting aside, it doesn't rise to the level of realism where I'd worry too much about the fake news potential either.
However, with human guidance and a carefully chosen domain, it can still do some very impressive things. I've suspected that adventure game graphics in the point-and-click vein could be one of those domains, and since I'm helping someone dear to me realize such a game, I had the excuse I needed to explore it a little and write this case study.
Inspiration
Point-and-click adventures make up a fairly broad genre with many different art styles. I've focused my attention on a sub-genre that hews close to the style of early 1990s Sierra and LucasArts adventure games. These would typically run at a screen resolution of 320×200 and appear pixelized, especially so on a modern display:
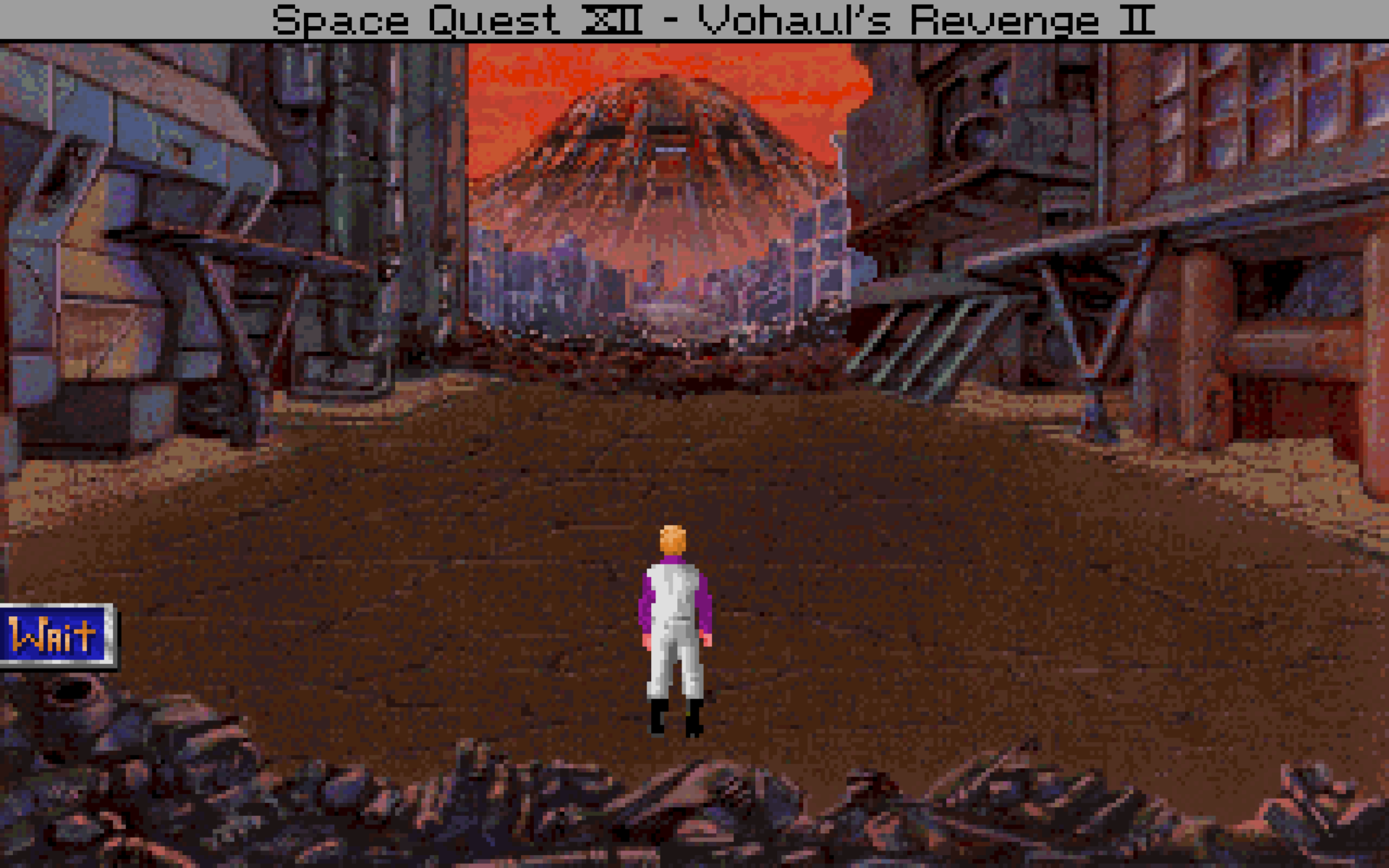

Contemporary game developers sometimes work at low resolutions, producing a similar effect:



At first glance this seems restrictive (just ask H.R. Giger), but from a certain point of view, it's actually quite forgiving and confers lots of artistic license:
- The perspective doesn't need to be realistic or even consistent, and is often tweaked for practical reasons, such as eliminating visual clutter, providing more space for the action or aligning better with the pixel grid.
- Speaking of pixels, pixelization helps work around the fact that DALL-E can produce odd smudges and sometimes struggles with details. It also helps with manual retouching, since there aren't very fine details or textures to be precisely propagated.
- Does your art look weird? Uncanny valley anxiety? Take a free tour courtesy of the entire genre. Feel your troubles float away as it throws an arm around you. And another arm. And another.
Ahem. What I'm trying to say is, this is a wonderful, fun genre with many degrees of freedom. We'll need them!
How to into the pixels
While you can tell DALL-E to generate pixel art directly, it's not even remotely up to the task; it just doesn't know how a pixel grid works. The result will tend to have some typical pixel art properties (flattened perspective, right angles, restricted palette with colors that "pop") wrapped in a mess of smudged rectangles of all sizes:
It's impressive in a "holy guacamole, it kind of understood what I meant" way, but even if you clean up the grid you don't stand a chance of getting a consistent style, and you have no control over the grid size.
Fortunately, pixelization can be easily split off from the creative task and turned over to a specialist tool. I used magick in my scripts:
$ magick -adaptive-resize 25% -scale 400% in.png out.pngIt's worth trying different resampling filters. ImageMagick's -adaptive-resize operator produces nice and crisp output, but when downsampling by this much there may be even better options.
You could also experiment with color reduction and dithering. The images I generated for this article have been postprocessed like this…
$ magick -adaptive-resize 25% -ordered-dither checks,32,32,32 \
-scale 800% in.png out.png…which pixelizes to a 1:4 ratio, restricts the output to a color cube with 32 levels per channel (i.e. 15-bit color) and applies subtle — but not too subtle — checker-pattern dithering. It also upscales to twice the original size for easy viewing in a web browser.
Style prompts and selection
After some trial and error, I settled on a range of prompts involving techniques, styles and authors of fine art: oil on canvas, high renaissance, modernism, precisionism. This gave me a good chance of output in a handful of repeatable styles with sufficient but not overwhelming detail:


Beyond important details ("sunny day"), vague modifiers like "atmospheric", "dramatic" and "high quality" can have huge effects on lighting, camera angles and embellishment. They're also very unreliable, and I have the feeling they can crowd out more important parts of the prompt from the model's tiny mind and cause them to be overlooked. It's better to use compact, specific prompts until you're close, and then, well, watch it fall apart as you add a single modifier.
Which brings us to the second human-intensive part of this task: selection. Since the OpenAI UI produces four variants for each prompt, this is mandatory. It's also very necessary, as most of the output falls far short of the mark. With the right prompt, you might get a distribution where roughly 1/20 images is good (with minor defects) and 5/20 are potentially salvageable. The remainder will be obviously unusable for various reasons (major defects, stylistic and framing issues, photobombed by anthropomorphic utility pole).
I think it's the same way with the impressive DALL-E mashups being shared. By the time you're seeing them, they've been curated at least twice; once at the source, and one or more times by the chain of media that brought them to you. You won't see the hundreds of images that came out funny but not ha-ha funny.
Since each image takes only a second to generate and a few seconds to evaluate, this wild inconsistency isn't disqualifying. It just means DALL-E isn't magical or even very intelligent.
Setting the stage
An adventure game location is a bit like a theatre stage; it's a good idea to have an ample area close to the camera for the player to walk around in. It's also a good idea to avoid scenes where the player can get far away from the camera, as you'd be forced to choose between a comical perspective mismatch and a really tiny player character that'd be hard to follow and control. Obviously a real game won't want to follow these rules strictly, but it's important to be able to implement them when needed.
Fortunately it can be done, and it's not too hard:


To control the perspective and make it more flat, adding "facade" seemed to be effective. Ditto "diorama" and "miniature", although they tended to produce a more clinical look. Specifying a typical ground-level detail to focus on, e.g. "entrance", was also helpful. I'm not sure "2d" and "2.5d" actually made any difference. Bringing it all together:
- Specify the era, time of day and lighting conditions (e.g. "on a sunny day in the 2000s").
- Be specific about the overall location ("town", "city", or a named geographical location), the focus ("facade", "hotel entrance") and the immediate surroundings ("houses", "streets", "plains").
- You can explicitly ask for open space, e.g. "…and street in front" or "plaza surrounded by…".
- Sometimes it's necessary to ask for the space to be empty, otherwise DALL-E can paint in objects and people that you'd rather add as overlays later on.
- You can also specify camera placement, e.g. "seen from second-floor balcony", but you risk ground-level details becoming too small.
- Some combinations will have the model drawing blanks, resulting in ignoring much of your prompt or horking up non sequitur macro shots of blades of grass and the like. Be prepared to rephrase or compromise. Think about what might be well represented in the training set.
- Do not under any circumstance mention "video game", unless you want blue neon lights on everything.
Retouching and editing
This is easy to do using the in-browser UI. Just erase part of the image, optionally edit the prompt and off you go. Very useful for those times you've got something great, except there's a pine growing out of a church tower or an impromptu invasion of sea swine. Adding objects works too. Here's a villain's preferred mode of transportation, quite believable (if out of place) on the first try:

You can also upload PNG images with an alpha channel, although I had to click somewhere with the eraser before it would accept that there were indeed transparent areas. I suspect you could use this to seed your images with spots of color in order to get a more consistent palette.
Extending the images
DALL-E generates 1024×1024-pixel postage stamps. To fill a modern display you want something closer to a 19:10 ratio. Transparency edits come in handy here. The idea is to split the original image into left-right halves and use those to seed two new images with transparency to fill in:

This is easily scriptable. Note that you have to erase the DALL-E signature from the right half to prevent it bleeding into the result. Something like this can work:
$ magick in.png -background none -extent 512x0 -splice 512x0 left.png
$ magick in.png \( +clone -fill white -colorize 100 -size 80x16 xc:black \
-gravity southeast -composite \) -alpha off -compose copy_opacity \
-composite -compose copy -background none -gravity east -extent 512x0 \
-splice 512x0 right.pngUpload left.png and right.png, reenter the prompt and generate a couple of variants for each. Since there's lots of context, the results turn out pretty good for the most part. Then stitch the halves together like this:
$ magick +append left.png right.png out.pngWith a little more scripting, you can generate all possible permutations and apply your big brain judgement to them, e.g:


…and so on. You can also tweak the side prompts. Put in a pool or whatever:


I wouldn't be surprised if this kind of image extension made it into the standard toolbox at some point.
Other things it can do, and some that it can't
I had some success with interiors too. "Cutaway" was a handy cue to knock out walls and avoid claustrophobic camera placement, and it handled decorations and furniture fairly well (e.g. "opulent living room with a table and two chairs"). It could also generate icons for inventory items after a fashion ("mail envelope on black background"). I didn't delve very deeply into that, though.
You've probably noticed that the generated images all contain defects. Some can be fixed by erasing them and having DALL-E fill in the blanks, but others are too numerous, stubborn or minute for that to be practical. This means you'll have to go over each image manually before pixelization (for rough edits) and after (for the final touch). You'll also need to adjust colors and levels for consistency.
DALL-E can't write. In fact it will rarely be able to arrange more than three letters in a correct sequence, so if you want words and signage, you'll have to draw it yourself. Maps and other items that convey specific information by virtue of their geometry can probably also be ruled out, although you may get lucky using a mostly transparent cue sketch.
You won't get much help with animations, especially complex multi-frame ones like walk cycles.
If you want to convert an existing daylight scene into a night scene, that's probably best done manually or with the help of a style transfer model.
I realize I've barely scratched the surface here, and there's bound to be a lot more that I haven't thought of.
The economics of AI jackpot
OpenAI controls usage through a credit system. Currently, one credit can be used to generate four images from a single prompt, or three edits/variants from a single image and prompt. I got some free welcome credits (50 or so), and they're promising another 15 each month. When you spend a credit, it takes 4-5 seconds to get results, which means about a second per image. You can buy 115 credits for $15 + tax, which in my case works out to a total of $18.75. That's $0.163 per credit, or at most $0.0543 per image (batch of three).
Let's say you use this to generate locations for a point-and-click game. How many will you need? Well, one very successful such game, The Blackwell Epiphany (made entirely by the fine humans at Wadjet Eye Games), has about 70 locations. If you're considering AI-generated images for your game, you're probably not trying to compete with one of the industry's most accomplished developers, so let's lower that to 50.
50 locations is still a lot, and as I mentioned before, only 1/20 images come out adequate. For each location, you can probably get by with 10 adequate candidates to choose from. That means you'll generate 200 images per location, or 10,000 images total. Let's double that to account for some additional curation, edits, horizontal extensions, late changes to the script and plain old mistakes. Then, 20,000 * $0.0543 = $1,087. Since most of the images will be generated in batches of four, not three, it's fair to round that down to an even $1,000. It's probably not your biggest expense, anyway.
How about time investment? I mean, evaluating that many images seems kind of crazy, but let's do the math and see. If an image takes about 1s to generate and you spend about 5s deciding whether to keep it (recalling that 95% is quickly recognizable as dross and you'll be looking at batches of four), that's 20,000 * 6s = 120,000s or about 33 hours. Even if you can only stand to do it for two hours a day, you should be done in three to four weeks.
Throughout this you should be able to generate 10 candidates and 10 edits for each location. Further manual editing will likely take much longer than three weeks, but that's not something I'm experienced with, so I've really no idea. It also presupposes that you're starting out with a detailed list of locations.
Legal considerations
In addition to their API policies, OpenAI have public content policy and terms of use documents that appear to be specific to DALL-E. I'm not trained in law, but the gist of the content policy appears to be "don't be mean, sneaky or disgusting", which is easy for us to abide by with only landscapes and architecture. Some of the restrictions seem unfortunate from the perspective of entertainment fiction: Could I generate a bloodied handkerchief, a car wreck or something even worse? Probably not. Anything containing a gun? Certainly not. However, they're also understandable given the stakes (see below).
The most concerning thing, and likely a showstopper for some creative enterprises, is point 6 of the terms of use: Ownership of Generations. My interpretation of this is that generated images are the property of OpenAI, but that they promise not to assert the copyright if you observe their other policies (which may, presumably, change). If you're making a long-lived creative work, especially something like a game that may include adult topics alongside the generations, this seems like a risky proposition. I wouldn't embark on it without seeking clarification or some kind of written release.
Ow, my ethics!
So, yeah, ethics. An obvious line of questioning concerns misuse, but OpenAI is erring on the side of caution (or realistically, trying to keep the lid on just a little longer), and anyway, our use case isn't nefarious.
What's more relevant to us is the closed training dataset and how it might contain tons of formerly "open" but copyrighted material, or simply pictures whose author didn't want them used this way. We're talking half a billion images, and the relevant research and blog posts either allude to web scraping or mention it outright. A search for reassurance didn't turn up much, but I did discover an interesting open issue. So, could this be disrespectful or even abusive?
A common defense claims that the model learns from the training set the same way a human student would, implying human rules (presumably with human exceptions) should apply to its output. This can seem like a reasonable argument in passing, but besides being plain wrong, it's too facile since DALL-E is not human-like. It can't own the output (or, as the case would be, sign its ownership over to OpenAI) any more than a relational database could.
A better argument is that the training process munges the input so thoroughly that there's no way to reconstruct an original image. You don't have to understand the process deeply to see that this makes sense: there's terabytes of training data and only gigabytes of model. Then the implication becomes that this is transformative remixing and potentially fair/ethical use.
Thinking about this kind of hurts my head, particularly as it's also playing out in my own field. I haven't definitely concluded, but in general I think it's important to focus on the net good that technology and sharing can bring and how the benefits (and obligations) can be distributed equitably.
So is this going to upend everything?
Well, not everything. But some things, for sure. Neural networks have evolved very quickly over the past couple of years, and it looks like there's plenty of low-hanging fruit left. Current research leaves the impression that DALL-E 2 is already old news. There are also open efforts that seem to be completely caught up, at least for those with some elbow grease and compute time to spare.
A dear friend of mine joked that we've been privileged to live in a truly global era with minimal blank spots on the map and a constant flow of reasonably accurate information, the implication being that the not too distant past had mostly blank spots and the not too distant future will be saturated with extremely plausible-looking gibberish. We had a laugh about that, but you have to wonder.

A clarification regarding pixelization
August 18th: This article sort of made the rounds, and there has been lots of interesting feedback. Contrary to conventional wisdom, my experience when this happens is that other netizens are mostly very thoughtful and nice. So too this time.
There's one recurring criticism I should address, though, because I think it stems from my own carelessness and/or attempts at brevity: This is not pixel art!
Well, sure. It's not what we understand to be pixel art in 2022. Pixel art is when you hand-pixel the things, and maybe this could be too if it had gotten seriously retouched during/after pixelization — but in its current state it isn't. Since I'm aware of the distinction, I tried to word the article carefully ("adventure game graphics", "pixelization", "pixel graphics" in lieu of "lowres" or whatever) and only brought up pixel art in relation to the DALL-E query because, y'know, one can dream.
I sort of danced around it, though, and never explicitly said so. Here's the missing section:
An important reason I started out with a comparison to early 90s games (and not, say, any of the great 80s games) is that around that time, it became practical to make adventure game art using physical media (e.g. matte painting) and then digitizing it, which is somewhat similar to what I'm attempting here — except there's no need to digitize DALL-E's paintings (already digital). Instead, I added postprocessing as a callback to the traditional digitization process. Here's an excerpt from a nice Sierra retrospective by Shawn Mills. Go read the whole thing, it's great:
"We started painting with traditional media and then had our programming team develop some amazing codecs to scan the artwork in. That also allowed us to key scenes for other people and send them overseas to places like Korea and have them paint them. So we could really up the production because we [alone] never would have been able to raise the quality of production that we wanted."
Bill Davis, first Creative Director at Sierra On-Line
So Sierra got more for less, and they did this by sending prompts to dedicated overseas painters (vs. learning to paint faster/better or hiring more in-house). Sound familiar?
There's still the sort of "ugh" reaction one might have to talking about efficiency and art in the same sentence, and I do feel that. It's more fun to learn a new skill, or to work closely with others.
What's not fun, though, is to watch a nice, practical article that's already way too long start to overflow with the author's opinions and speculation. That's what the comments are for.
Really interesting post with some beautiful pics… i look forward to the game!
HP, many thanks! interesting read and useful input on how to make DALL-E iterate in ones desired way. I entertain the idea of trying it out. Did you btw read about google's new AI developments?
I've read a bit about Imagen, but haven't been able to check it out yet. The impression I have is that it beats DALL-E in some metrics even while conceptually simpler. See: https://github.com/lucidrains/imagen-pytorch
Serious training usually relies on cloud compute, but if you're a bit technical and have a decent GPU, it shouldn't be too hard to get started running pre-trained models on a home computer. I did some work with Torch/PyTorch years ago, and as always, the biggest difficulty was getting the graphics drivers to cooperate 🙂
Cool post, thanks for sharing!
If you are making a horror game you can also ask it to create sprite sheets for you: https://labs.openai.com/s/8B4slIjM974bCnL4aV413xbC
Hah. Morbidly curious to see those looped now.
Let calppey!
Let calppey o7
I came here via https://news.ycombinator.com/item?id=32490455 after talking with kjellesvig.
This is what you mentioned last time we met. Very cool that you realized your game graphics idea with DALL-E 2 queries.
Amazing article. Hope we’ll a lot of ai art in products and art soon, this is more than a domain evolution. Thanks for sharing!
Really Cool. I hope that this will increase the number of people who enter the game development. After the Tsukuru Game Maker, this is a new revolution!
What you have explained here in this article is _exactly_ pixel art, i.e., "art made up of visible square pixels" (pixels are squares/rectangles, btw). Anyone who disagrees is talking about something else. Perhaps they're talking about human-placed-pixel art, or hand-coded-pixel art, or something along those lines. Like I said: something else.